Overleaf 模板库LaTeX 模板和示例 — Recent
探索 LaTeX 模板和示例,以帮助完成从撰写期刊文章到使用特定 LaTeX 包的所有工作。

Erciyes Üniversitesi Bilgisayar Mühendisliği Bölümü'nde kullanılan "Bitirme Ödevi" dersi tez öneri formatı

A template for creating course homeworks. The template uses the same style file so as to avoid the need for long preamble. The 'Main Document' should be set to the homeworks you are working on.

This is a basic Icelandic template, containing most of the packages that need to be used.

Proposta de presentació per als pòsters de la assignatura Projecte 3 del Grau de Geografia de la URV.
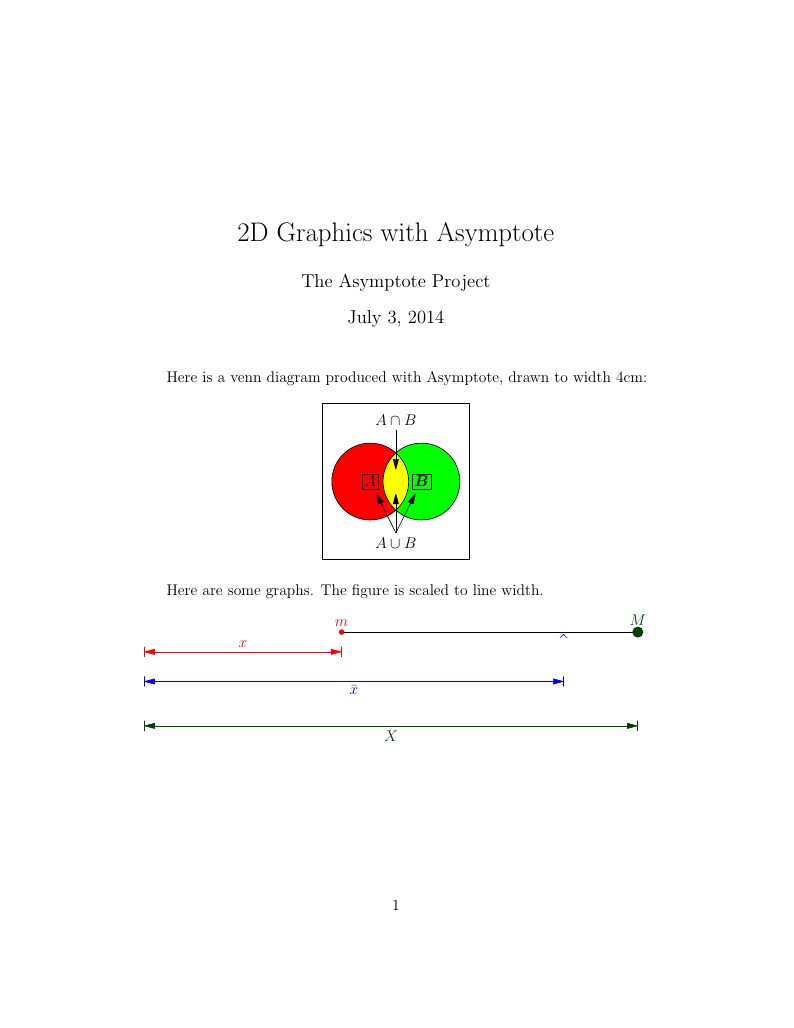
This example shows how you can use Asymptote on writeLaTeX. Asymptote is a powerful vector graphics language for technical drawings. Labels and equations are typeset with LaTeX, for high-quality output.

A template for fibeamer, the beamer theme for the typesetting of thesis defense presentations at the University of Brescia (Italy). For more information about the theme, see https://www.fi.muni.cz/lemma/projekty/fithesis3#fibeamer.

PhD Thesis format of Indian Institute of Technology Bombay

Fatih Sultan Mehmet Foundation University Turkey, Computer engineering department thesis template. Fatih sultan mehmet vakif unviersitesi tez şablonu

Plantilla de Working Paper para la Editorial SoPhIC. Para resolver dudas relacionadas con el uso de esta plantilla por favor contactar a editorial@sophicol.org